当我们谈论DeepSeek时,很少会提及多模态。
然而,10月20日,DeepSeek突然开源了DeepSeek-OCR。看起来,它是一个OCR(光学字符识别)模型,并且在OmniDocBench等权威基准上取得了SOTA(业界顶尖)的成绩。

那它为什么要突然涉足OCR领域?答案藏在当前大语言模型面临的最大挑战中:长上下文处理的算力瓶颈。
这篇论文的核心论点是:文本信息可以通过光学2D映射(即渲染成图像)被高效压缩,然后让VLM(视觉语言模型)从图像中解压出原始信息。
简单来说,就是将文本内容转换为图像形式,用比等效数字文本少得多的视觉token来表示相同的信息。
对此,大神AndrejKarpathy也表示深受该论文启发,感觉可能像素(pixels)是比文本(text)更好的LLM输入。
还列举了这么做的四大好处:
信息压缩:他明确引用了DeepSeek-OCR论文的观点,这将带来“更短的上下文窗口和更高的效率”。
更通用的信息流:输入不再局限于纯文本,还可以包含“粗体、彩色文本、任意图像”。
更强的处理方式:图像可以被“双向注意力”(bidirectional attention)轻松处理,这比文本常用的自回归注意力“强大得多”。
删除(输入端的)Tokenizer”:这是他最激动的一点。他借此强烈抨击了现有的分词器这个老大难问题。

本文将深度解析这一构想,探讨DeepSeek为何要用视觉这把锤子来敲文本这颗钉子。这一论文,很有可能会用一图胜千言的模式,改变以后LLM的整个输入范式。
01 名为OCR,实为长上下文
在LLM的世界里,一切竞争的尽头,似乎都是对“更长上下文”的追求。从几千token到几万,再到今天的百万、千万token窗口,这场军备竞赛从未停歇。
其背后的根本制约,源于Transformer架构的灵魂,注意力机制。
标准的全局注意力,允许序列中的每一个token都看到所有其它token,这赋予了模型强大的上下文理解能力。但在当前主流的自回归模型中,这种能力的代价是高昂的:因为每个token都要和前面所有token建立起乘积关系去预测下一个token,因此其计算复杂度和内存占用随序列长度成二次方增长。
尽管业界已经提出了分组注意力、多查询注意力、RoPE位置编码等优化技术来减少查询头的数量,但这些方法本质上都是试图优化中的那个token计算的平方复杂性,却从未真正减少token数量本身。
DeepSeek-AI团队的工程师们显然注意到了这个房间里的大象。他们跳出了优化注意力计算的内卷,提出了一个更根本的问题:我们能不能把token数量本身给“压缩”掉?
这就是光学压缩(Contexts Optical Compression)的逻辑起点。
想理解这个,我们得先弄明白视觉token和文本token的不同。
视觉token是视觉模型处理图像时所使用的基本信息单元。文本模型(LLM)阅读的是文本token(单词或子词),而视觉模型(VLM)观看的就是视觉token。
在DeepSeek-OCR 论文中,视觉token是先将高分辨率图像切割成小的图像块,在编码过程中,每个小图像块本身都会被转换成一个数字向量(即一个token),而这个向量就代表了该图像块的全部信息。因此一张1024*1024的图像就可以被划归成4096个视觉token。
而大小为其一半的图像能容纳的文字量大概是10000个文本token。
因此,一张包含10000个单词的文档图像,经过视觉化后的token量就少了一半,再经过图像压缩,则可能只需要几百个视觉token,而如果以文本形式输入则需要10000多个文本token。这种“视觉模态天然就是文本信息的高效压缩媒介”的认知,催生了DeepSeek-OCR这个项目。
DeepSeek-OCR本质上是一个“光学压缩-解压”系统的概念验证。它试图回答一个根本性问题:用多少个视觉token,能够解压出多少倍的文本token?
这个问题的答案,将直接决定“视觉压缩”作为长上下文解决方案的可行性。DeepSeek目前的方案,实现了10倍压缩,几乎无损,20倍压缩,基本可用。
02 DeepEncoder,压缩的艺术
要实现光学压缩,团队需要一个前所未有的视觉编码器。它必须能处理高分辨率输入(因为文本图像包含海量细节),产生尽可能少的视觉token。同时,这个过程中,激活内存要够低(否则就失去了优化的意义)。
论文明确指出,当时所有的主流VLM架构(如Vary、InternVL2、Qwen2-VL)都无法同时满足这三点。
为此,DeepSeek-AI设计了这篇论文的第一个核心技术创新:DeepEncoder。
DeepEncoder 是一个约3.8亿参数的串联架构,它的工作流很像个情报处理团队,形成一个三级串联的架构。
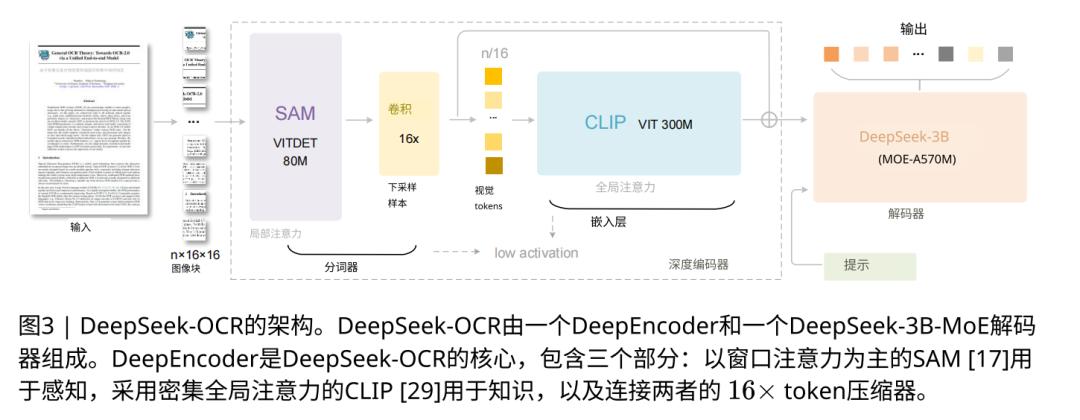
第一级是一个80M参数的SAM-base感知器。它就像个搜集情报的特工,专门负责处理高分辨率输入的局部细节。当面对1024×1024的图像时,它会将其分解为4096个图像块,但通过窗口注意力机制,将计算严格限制在小窗口内部,从而在处理海量局部token时保持极低的激活内存。
第二级是整个架构的关键,是一个16倍压缩器(Conv 16x) 。它的角色像一个信息汇总员,是一个2层的卷积模块。它接收来自第一阶段的4096份“原始情报”,并通过一个可学习的16倍下采样,将其“压缩提炼”成一份仅有256条视觉token的“摘要简报”。它在训练中被教会了如何保留对“解压文本”最重要的特征。
第三级是一个300M参数的CLIP-large知识层,它就像个总指挥官。这一部分不看那4096份原始情报,他只看这份256条的摘要简报。因为简报足够短,他可以奢侈地使用昂贵的全局注意力(Global Attention),对这256条精华信息进行全面的交叉对比和精细观察,从而理解这些压缩token之间的长距离关系和全局语义结构。
编码器(DeepEncoder)输出的256个token,只是一个全局视觉摘要。真正负责按顺序复述出完整上下文的,是后续的解码器 DeepSeek-3B-MoE 。DeepSeek-3B-MoE 接收到这个视觉token的摘要,生成文本。它会参考DeepEncoder给出的全局摘要中的“中间部分”的视觉证据,同时用自己的语言模型来确保上下文的连贯。
DeepEncoder 这种先局部、再压缩、后全局的串联设计,完美地规避了所有之前解决方案的问题。
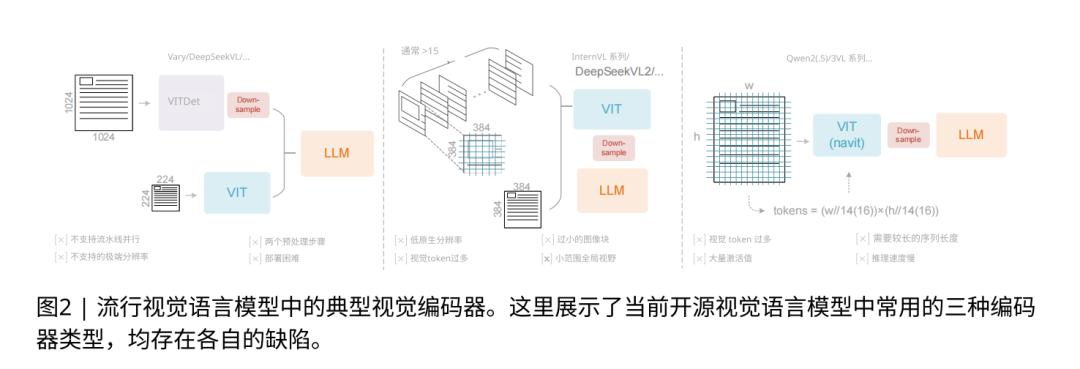
Vary像两个独立专家,一个看细节一个看轮廓,LLM最后自己去猜。DeepEncoder 则是单路串联,信息逐级提炼,架构更优。
InternVL2则是把大图切成海量碎片,产生几千个token,也不具备全局性和压缩能力。DeepEncoder通过内部压缩,只产生几百个token。
Qwen2-VL试图对几千个token直接用全局注意力,很容易导致显存爆炸。DeepEncoder 则只对压缩后的256个token用全局注意力,成本可控。
这种“先局部感知,再压缩提炼,后全局理解”的设计哲学,完美解决了高分辨率处理和低计算成本之间的矛盾。
实验结果证明了这一设计的有效性:
10倍压缩率: 当使用64个视觉token(Tiny模式)解码600-700个文本token时,压缩率达到 10.5倍,OCR精度高达 96.5%。
20倍压缩率: 当压缩率飙升到近 20倍时(如用64token解码1200+token),模型精度会下降,但依然保持在 ~60% 的可用水平。
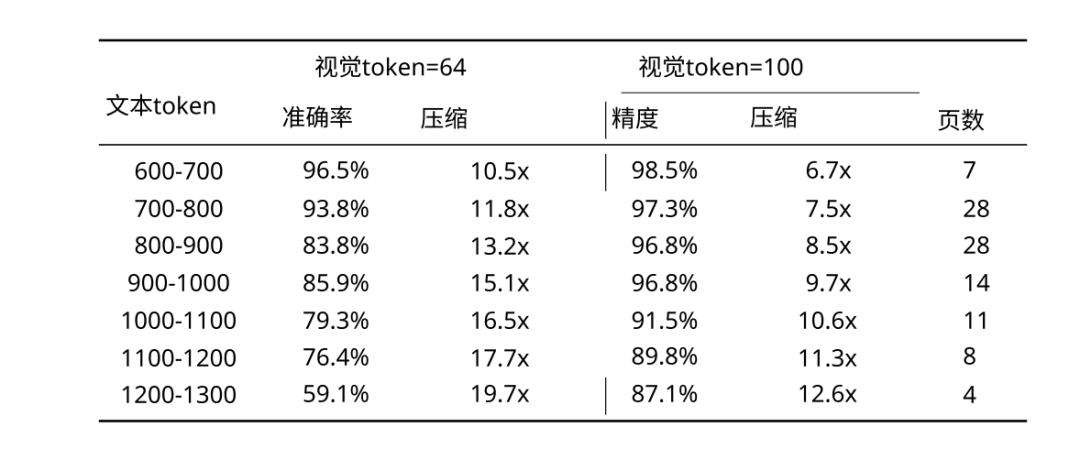
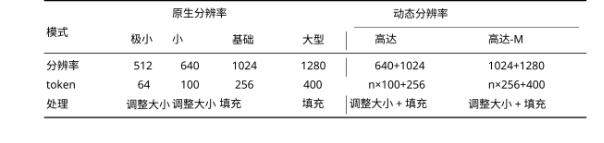
Deepseek OCR所需的tokens数量会随文档类型而变化:简单演示文稿约需64tokens;书籍和报告约需100tokens;复杂的报纸内容则需启用所谓的“高达模式”(Gundam Mode),最高使用800tokens。
在实际的OCR基准OmniDocBench上,它更是实现了降维打击:
DeepSeek-OCR(Small模式)仅用100个视觉token,性能就超过了使用256个token的GOT-OCR2.0。
DeepSeek-OCR(Gundam模式)使用不到800个视觉token,性能全面超越了需要近7000个token的MinerU2.0。
这意味着,用这种方法,实际上可以做到当下上下文极限长度的十倍,而不降低其准确率。而且因此其压缩效率,单颗英伟达A100 GPU即可每日处理超过20万页文档;若配备20台服务器(每台搭载8颗A100 GPU),系统的日处理能力可提升至约3300万页。
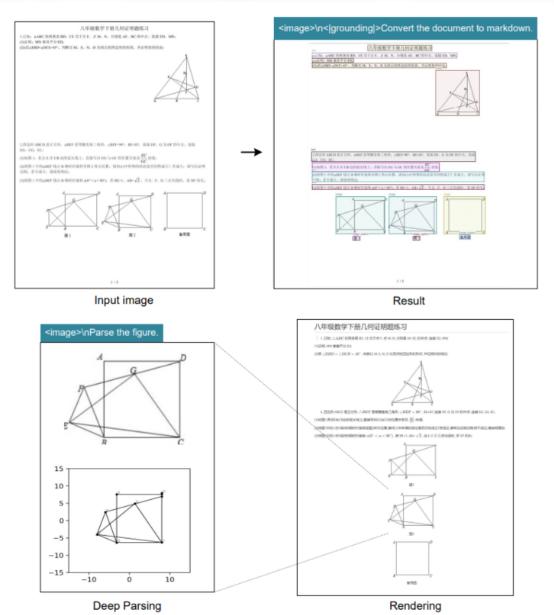
DeepSeek-OCR还可识别并处理多种文档类型,包括纯文本、图表、化学式与几何图形。它支持约100种语言,既能保持原始版式,又能输出纯文本或生成图像内容描述。

更重要的是,这种方法不需要任何额外的基础设施成本,因为多模态系统本身就需要视觉编码器。
DeepSeek-OCR实际上是在现有的VLM基础设施上,实现了一种全新的文本压缩范式。
03 窗口注意力的回响
其实DeepSeek所用的方法会多少让人有点眼熟。因为在Transformer统治一切之前,在BERT和早期RNN的时代,窗口是最主流的妥协方案。
无论是RNN的BPTT(随时间反向传播)截断,还是BERT为代表的模型所采用的滑动窗口(Sliding Window),其逻辑都是:模型无法一次性处理全部上下文,那就只看一个固定大小的窗口。
这其实和DeepSeek-OCR有点像,它也是把上下文截成一个个压缩后的图像信息去处理。
但过去的方法无法处理信息孤岛效应。当注意力被严格限制在局部窗口内时,模型失去了理解长距离依赖关系的能力。一个文档的标题可能无法与其对应的图表产生有效的关联,因为它们被困在不同的“注意力窗口”中。这种局限性使得传统窗口方法在需要全局理解的任务中表现不佳。
但在Transformer时代,这个方法的内在机制已经发生了质变。它继承了窗口注意力计算高效的优点,同时通过混合架构设计巧妙地解决了信息孤岛问题。
这里面,先验知识 (Prior Knowledge)是最关键的区别。BERT的窗口是缺乏先验知识的,它对处理的内容一无所知。而DeepSeek-OCR的编码器和解码器都是经过大规模预训练的模型,它们对视觉结构、文本布局、语言规律都有深刻的理解。这种丰富的先验知识使得模型即使在高度压缩的情况下,也能通过“智能推理”重建出原始信息。
因此,DeepSeek-OCR的方案不是对窗口注意力的简单复刻,而是一次彻底的范式革新。
它用基于先验的感知压缩取代了基于邻近性的无知截断,在保留全局视野的同时,实现了比传统窗口高效得多的信息保真度。
04 终极愿景,用光学遗忘模拟人类记忆
如果说10倍的上下文压缩率是DeepSeek-OCR的里子,那么它在论文第五章讨论和结论中展露的野心,就是它真正的灵魂。
团队提出了一个极具想象力的宏伟目标:模拟人类的遗忘机制。
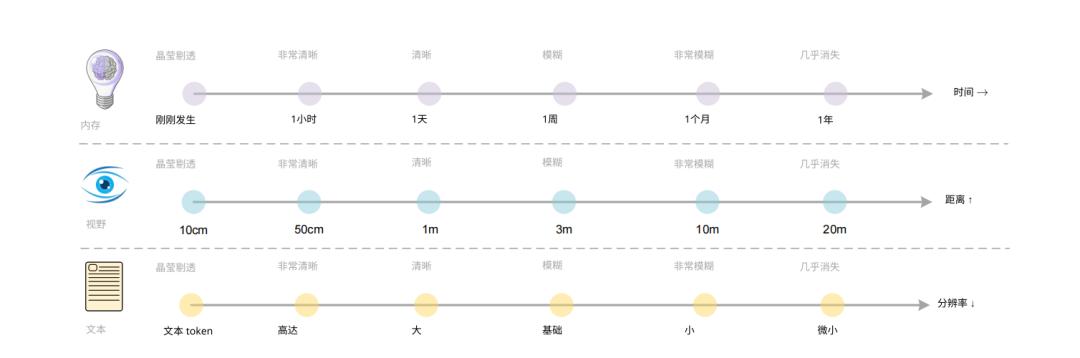
人类的记忆系统具有天然的分层和衰减特性。刚刚发生的事件在我们的记忆中晶莹剔透,几个月前的经历变得模糊不清,而多年前的记忆可能几乎消失。这种遗忘不是系统的缺陷,而是一种高效的信息管理机制。
它确保大脑将有限的认知资源分配给最相关、最重要的信息,同时通过压缩和模糊化来保留远期记忆的要点。
有趣的是,人类的视觉感知也表现出类似的距离衰减特性。我们对10厘米处的物体看得晶莹剔透,对20米外的景象则几乎看不清。
DeepSeek-OCR的多分辨率设计,恰好提供了模拟这种衰减机制的技术基础。
AI系统可以采用以下策略来管理其记忆:对于近期的上下文(比如最近几轮对话),系统可以保留为高精度的文本token,或者渲染成高分辨率图像用Gundam模式(高token数)处理,确保信息的完整保真;对于中期上下文(比如10轮前的对话),可以渲染成图像并用Base模式(256token)处理,信息开始变得模糊但仍然可用;对于远期上下文(比如100轮前的对话),可以进一步降低渲染分辨率,用Tiny模式(64token)处理,信息高度压缩但仍保留核心要点。
在实际应用中,把过去的上下文作为模糊记忆,利用OCR去使用的流程会更像这样:
1. 模型完成今天的对话后,将“昨天的对话”渲染成一张或几张图片。
2. 模型将这张历史图片喂给 DeepEncoder。DeepEncoder 对其进行全局感知和压缩,最后输出一套极少数的视觉上下文token(比如用Base模式,输出256token)。
3. 当您今天输入新的问题时(比如有50个token),模型会在内部将您今天的token(50个)和那256个代表昨天的视觉token拼接在一起。
4. 模型的解码器(如 DeepSeek-3B-MoE)现在只需要处理 $50 + 256 = 306token,它会对这两组token(一组是文本,一组是视觉)同时进行注意力计算,然后生成对您今天问题的回答。
这种分层记忆机制的最大价值在于,它提供了一条通往“理论上无限上下文”的可能路径。传统的长上下文技术要么通过滑动窗口彻底丢弃历史信息,要么试图保留所有细节而导致计算成本爆炸。
而“光学遗忘”机制通过渐进式的信息压缩,在保留历史要点和控制计算成本之间实现了动态平衡。
然而,这个优雅的机制是否完美?它目前还不是。
DeepSeek-OCR当前所展示的压缩,是一种无选择性的均匀压缩。它就像我们调整图像分辨率,图像上的所有内容,都会被同等程度地模糊掉。
这显然不符合人类的记忆机制。我们人类的遗忘是有选择性的,它与注意力和重要性高度相关。我们会牢牢记住婚礼上的誓言,却会迅速忘记早餐吃了什么。
DeepSeek-OCR目前还做不到这一点。它用Tiny模式压缩的1天前的对话,很可能把关键信息和垃圾信息一起忘掉了。
但这个范式,指明了下一座要攀登的高峰。
DeepSeek-OCR只是第一步,它验证了光学压缩这个机制的可行性。第二步,就是让压缩变得有选择性。它为AI的记忆、遗忘和输入机制提供了一个全新的技术框架。
有时候忘记和压缩,比记住和保留更加重要。
这篇文章更重要的范式意义,可能是输入上统一的可能,因为图像这个模态其实更合乎人类认知。
当我们人类阅读时,我们并不是在处理抽象的文本token,而是在用视觉系统处理屏幕或纸张上的像素、形状和布局。我们的大脑首先是一个强大的视觉处理器,然后才是语言解码器。
因此Karpathy提出了那个激进的设想:所有给LLM的输入都应该先被渲染成图像。并非毫无道理,因为这可能才是更自然、更高效的信息流。
这也许才是一条真正模拟了人类认知和遗忘的、通向无限上下文的,AGI记忆和输入系统的新路径。
本文来自微信公众号“腾讯科技”,作者:博阳。